在今天 OpenAI 首届开发者大会上,Assistant Feature 和它具有的 Threading、Knowledge Retrieval、Code Interpreter、Function Calling 能力一经发布就引爆了各大论坛和公司群。
OpenAI 发布了什么?
在今天 OpenAI 首届开发者大会上,OpenAI 发布了 Assistant API 这一重磅更新,并推出了 Threading、Knowledge Retrieval、Code Interpreter、Function Calling 四大能力,可谓是今年最激动人心的科技新闻之一了。
自去年 11 月份 ChatGPT 发布后,我们已经看到了 AI 给人类社会带来的一些变化。和元宇宙这类没有技术突破仅仅是人造概念的噱头不同,AI 现在已经广泛运用于图片生成、语言助教、翻译、语言润色、代码问答、人格模拟等等场景,当初一度以为像 DeepL、Grammarly、CSDN 甚至百度搜狗这样的平台都会被蚕食掉很大一部分市场。当然这些平台确实多多少少受到了影响,比如我已经习惯于有问题先问问 ChatGPT 看看有没有最直接的解答,然后才决定要不要去 Google,但是在国内不可抗力和越来越多公司都在接受 AI “改造” 的情况下,互联网格局显然不会有大变化。
那为什么说今天的开发者大会如此重要呢?因为它推出的新功能解决了当今最强自然语言 AI ChatGPT 的一些痛点:
- 无法预先学习客户提供的知识,比如我没办法让它读完一本新写的书,因为这本书不在它的知识库里;
- 没有连续对话支持,每次调用它的 API 都需要发送对话的全部上下文,而这个上下文是有长度限制的;
- 没有真正的推理和执行能力,在数学计算方面尤其明显,它很可能给你一个错误的计算结果,因为它并没有真正的执行计算;
而有了 Assistant API,上面这些问题统统可以解决。
什么是 Assistant API?
Assistant API 和 ChatGPT 是大模型的两种不同的应用,ChatGPT 是使用 GPT 模型进行对话沟通的一种 API 以及 OpenAI 为它制作的前端网页,Assistant 同样使用 GPT 模型,但它可以接受代码、pdf、图片等不同类型的输入,并输出格式化的数据,是具有多模态输入输出的 GPT 应用。
也就是说现在 GPT 可以很轻松的读完一本上百页的 PDF 论文(甚至以后可能会看懂里面的图片),然后回答你关于这篇论文的问题。
可能你会觉得:我已经见过 ChatPDF 之类的应用,它们同样可以读取 pdf 然后回答问题,和现在的 Assistant 有什么区别?
ChatPDF 这类工具的工作原理是早就写在 OpenAI Cookbook 中的,实际上 AI 并不会读完整篇 PDF,而是先把 PDF 的内容保存到向量数据库中,然后将用户的输入做一次相似度查询(这个过程没有 AI 参与,完全是文本查询),再将相似度最高的数据送给 ChatGPT 回答。
在 ChatPDF 这种工作模式下,AI 根本没有理解 PDF 的内容,它只能回答原文中有明显的直接的答案,还很有可能是错的。但现在我们可以说,Assistant 真的可以读懂一篇 PDF 了。
Assistant API 有哪些能力?
初代 Assistant 开放了下面这四个主要功能:
- Threading:提供持久保存且无限长度的上下文,开发人员可以不用关心上下文的存储了,而且更省钱
- Knowledge Retrieval:检索用户上传的文件内容,并在未来可能支持开发者自定义检索方式
- Code Interpreter:执行用户上传的脚本文件来解决问题,可以上传多个脚本,AI 自己会选择何时执行
- Function Calling:调用第三方函数,只需要告诉 AI 函数功能和请求格式,AI 自己会选择何时执行
Assistant API 会产生什么影响?
Assistant API 绝对会很大程度上提升各种场景的工作效率,之前 ChatGPT 一个很大的问题是中文语料不足,导致很多功能无法实现,但是现在我能很快想到的功能就比如:
- 把法律条文输进去,用
Retrieval解决律师咨询贵的问题,哪怕只是让 AI 给出初步建议(国内已经有像ChatLaw这样可用的产品了,但是现在人人都可以自己做一个,是不是有点不讲道理?) - 做一个
GameGPT,把游戏背景什么的统统输进去,让 Assistant 模仿各种 NPC,这个 NPC 甚至可以永久记得它和玩家的对话 - 儿童 Python 助教,不仅可以把课程内容提前输入给 AI,还可以让 AI 自己执行简单代码来验证孩子的学习成果
- 各种 AI 客服,终于能让 AI 客服自己读懂产品内容,然后给用户回答有用信息了,效果不错的话那些需要人工客服的大厂会不会迎来一波裁员?
相信国内做大模型的厂商也已经在加紧模仿了,估计用不了多久就会出现各种各样的 Assistant,又是一波 KPI 啊。
Assistant API 功能尝鲜
Threading 测试
Threads API 要绑定 Assistant 使用,一个简单的示例:
- 创建 Assistant
from openai import OpenAI
client = OpenAI()
assistant = client.beta.assistants.create( name="test", instructions="You are a customer support chatbot. Use your knowledge base to best respond to customer queries.", model="gpt-3.5-turbo-1106",)- 创建 Thread
thread = client.beta.threads.create() # (可选)在创建时指定对话内容- 塞入 message
message = client.beta.threads.messages.create( thread_id=thread.id, role="user", content="Compose a poem that explains the concept of recursion in programming.",)- 执行 thread
Thread 默认不会运行,需要创建一个 Run 任务来执行 Thread。
run = client.beta.threads.runs.create( thread_id=thread.id, assistant_id=assistant.id,)- 等待 thread 执行完毕
Thread 是异步执行的,需要轮询检查是否执行完成。Thread 执行时会上锁,在执行完成前不可以再添加 message 或者提交新的 Run 任务。
while True: run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=run.id) if run.status not in ["queued", "in_progress"]: break time.sleep(1)- 获取 AI 输出结果
messages = client.beta.threads.messages.list(thread_id=thread.id)Knowledge Retrieval 测试
创建一个具有 Knowledge Retrieval 功能的 Assistant,并上传一个 PDF 文件让它检索
# 上传 PDF 文件file = client.files.create( file=open("Flexera-State-of-the-Cloud-Report-2023.pdf", "rb"), # 我用来测试的 PDF purpose='assistants',)
# 创建 Assistantassistant = client.beta.assistants.create( name="test-retrieval", instructions="You are a customer support chatbot. Use your knowledge base to best respond to customer queries.", model="gpt-3.5-turbo-1106", tools=[{"type": "retrieval"}], file_ids=[file.id],)用同样的方式创建 Thread,但是在添加 message 时指定 PDF 文件
message = client.beta.threads.messages.create( thread_id=thread.id, role="user", content="According to the PDF report, what are the most popular container tools in companies?", file_ids=[file.id],)这里我上传了 State of the Cloud Report by Flexera (2023) 这个 PDF,并问它公司里最流行的容器工具是什么,下面是它的回答:
User:According to the PDF report, what are the most popular container tools in companies?
Assistant:According to the Flexera 2023 State of the Cloud Report, the most popular container tools in companies are as follows:- AWS ECS/EKS: 45% currently use, 22% plan to use- Kubernetes (not via a cloud provider service): 40% currently use, 22% plan to use- Azure Kubernetes Service (AKS): 38% currently use, 23% plan to use- Docker: 42% currently use, 15% plan to use- Google Kubernetes Engine (GKE): 23% currently use, 22% plan to use- Red Hat OpenShift: 17% currently use, 18% plan to use- Docker Swarm: 13% currently use, 18% plan to use- SUSE Rancher: 8% currently use, 15% plan to use【19†source】.Assistant 找到了 PDF 中的答案,对应 PDF 第 47 页中的:
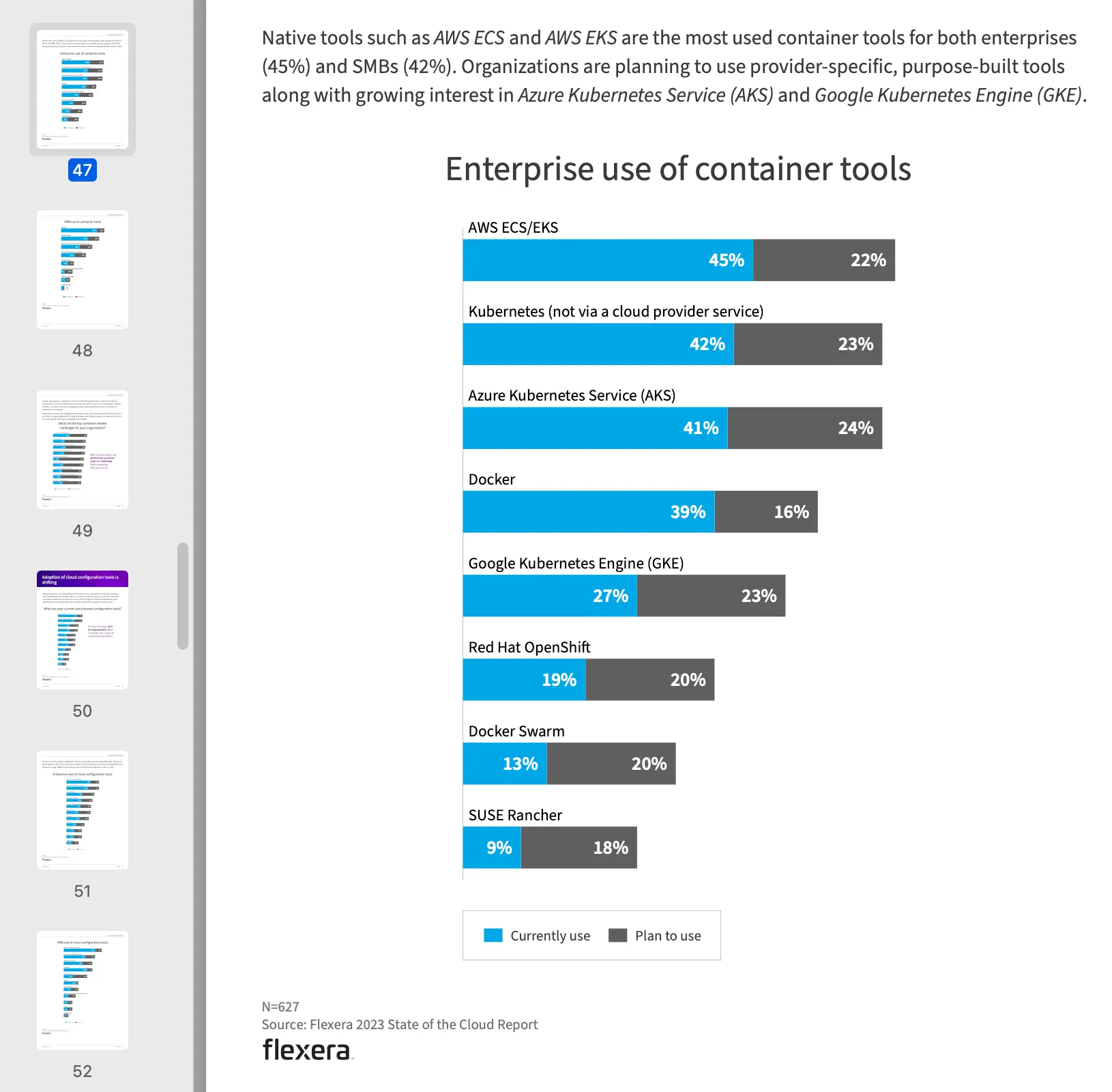
从结果来看它并不是简单的做一个向量查询然后让 AI 复述,毕竟这段文字中并没有定义什么是 popular,只是提供了每个容器工具的使用占比,而且是用柱状图的形式提供的,它也能精准定位。
Code Interpreter 测试
创建一个具有 Code Interpreter 功能的 Assistant,并上传一个脚本 文件让它检索
# 上传脚本文件file = client.files.create( file=open("speech.py", "rb"), purpose='assistants')
# 创建 Assistantassistant = client.beta.assistants.create( name="test-code-interpreter", instructions="You are a personal math tutor. When asked a math question, write and run code to answer the question.", model="gpt-3.5-turbo-1106", tools=[{"type": "code_interpreter"}],)用同样的方式创建 Thread,但是在提问数学问题时指定这个文件
message = client.beta.threads.messages.create( thread_id=thread.id, role="user", content="I need to solve the equation `3x + 11 = 14`. Can you help me?", file_ids=[file.id],)这是官网的示例代码,它没有提供 speech.py 这个文件,但是我们可以用 GPT 生成,下面是我生成的脚本:
from sympy import symbols, Eq, solve
# 创建符号变量x = symbols('x')
# 输入方程equation_str = input("请输入一元一次方程: ")
# 解析方程字符串equation_parts = equation_str.split('=')left_side = eval(equation_parts[0].strip())right_side = eval(equation_parts[1].strip())
# 创建方程式equation = Eq(left_side, right_side)
# 解方程solution = solve(equation, x)
# 输出解print("方程的解为 x =", solution[0])提交 Thread 后,这是 AI 的输出:
User:I need to solve the equation `3x + 11 = 14`. Can you help me?
Assistant:Certainly! I will solve the equation `3x + 11 = 14` to find the value of x. Let me start by solving this equation for you.
Assistant:The solution to the equation 3x + 11 = 14 is x = 1.它成功解出了这个方程,结果是 x = 1。这里有个神奇的地方,我们提供的脚本并不能接受 3x + 11 = 14 这个输入,因为它使用 python 的 eval 解析表达式,所以 3 和 x 中间需要一个乘号,也就是 3*x + 11 = 14 才是正确输入,那 AI 是如何知道这一点的呢?
通过获取它执行的 steps,我们可以看到它的执行过程
run_steps = client.beta.threads.runs.steps.list(thread_id=thread.id, run_id=run.id)print(run_steps)打印的结果如下
SyncCursorPage[RunStep]( data=[ RunStep( id="step_xxx", status="completed", step_details=MessageCreationStepDetails( message_creation=MessageCreation( message_id="msg_xxx" ), type="message_creation", ), ... # 省略 ), RunStep( id="step_xxx", status="completed", step_details=ToolCallsStepDetails( tool_calls=[ CodeToolCall( id="call_xxx", code_interpreter=CodeInterpreter( input="from sympy import symbols, Eq, solve\n\n# Define the variable\nx = symbols('x')\n\n# Define the equation\nequation = Eq(3*x + 11, 14)\n\n# Solve the equation for x\nsolution = solve(equation, x)\nsolution", outputs=[ CodeInterpreterOutputLogs(logs="[1]", type="logs") ], ), type="code_interpreter", ) ], type="tool_calls", ), type="tool_calls", ... # 省略 ), RunStep( ... # 省略 ), ],)其中最关键的部分是 code_interpreter 的输入输出,输入是一段脚本
from sympy import symbols, Eq, solve
# Define the variablex = symbols('x')
# Define the equationequation = Eq(3*x + 11, 14)
# Solve the equation for xsolution = solve(equation, x)solution它好像自己写了一个脚本去执行,并没有用我们上传的脚本。我也测试了一下不上传脚本文件直接提问,它的 steps 中同样可以产生类似的输入,看起来它只是可能使用上传脚本,并不稳定。
Function Calling 测试
我没有测试这个功能,按官网的教程,调用 Function Calling 需要下面几个步骤
- 创建 Assistant 时定义第三方 functions
# 定义两个 function# getCurrentWeather 获取当前天气# getNickname 获取城市昵称assistant = client.beta.assistants.create( instructions="You are a weather bot. Use the provided functions to answer questions.", model="gpt-4-1106-preview", tools=[{ "type": "function", "function": { "name": "getCurrentWeather", "description": "Get the weather in location", "parameters": { "type": "object", "properties": { "location": {"type": "string", "description": "The city and state e.g. San Francisco, CA"}, "unit": {"type": "string", "enum": ["c", "f"]} }, "required": ["location"] } } }, { "type": "function", "function": { "name": "getNickname", "description": "Get the nickname of a city", "parameters": { "type": "object", "properties": { "location": {"type": "string", "description": "The city and state e.g. San Francisco, CA"}, }, "required": ["location"] } } }])- 进行提问
提问 San Francisco 当前的天气怎么样,然后执行 Thread,并在 retrieve 步骤检查 Run 对象进入了 status=requires_action 这个状态。
- 执行三方函数
Run 对象会要求执行 getCurrentWeather 这个 function,但因为它不会真的调用接口,所以只是以 JSON 格式给出了请求体
{ "id": "run_3HV7rrQsagiqZmYynKwEdcxS", "object": "thread.run", "status": "requires_action", "required_action": { "type": "submit_tool_outputs", "submit_tool_outputs": { "tool_calls": [ { "tool_call_id": "call_Vt5AqcWr8QsRTNGv4cDIpsmA", "type": "function", "function": { "name": "getCurrentWeather", "arguments": "{\"location\":\"San Francisco\"}" } } ] } }}- 回传函数执行结果
使用它提供的 JSON 请求体手动调用接口获取天气,然后把结果回传给 Assistant
run = client.beta.threads.runs.submit_tool_outputs( thread_id=thread.id, run_id=run.id, tool_outputs=[ { "tool_call_id": call_ids[0], "output": "22C", }, ])此时 Thread 会继续执行,最后输出结果。