什么是 function score
function_score查询用于控制查询文档的评分,可以把它看做一个套子,套在你的任何查询之上,专门用来修改结果的分值。
这个查询常见的使用场景有两个,一个是简单的 modify 每个文档的评分,另一个是为了方便自定义排序,比如用来实现一个归一化评分的结果排序。
在第二种场景下,直接使用sort排序会过于绝对,因为它会忽略文档本身的相关度。比如按日期排序,得到的结果是绝对按日期排序的,query 本身的评分会被忽略。而function_score可以通过控制文档评分,间接达到排序的目的,使用起来更加灵活。
预定义的算分方法
一个简单的function_score的 DSL 格式如下:
{ "query": { "function_score": { "query": { "match_all": {} }, "weight": 2 } }}function_score包裹了一个query,这里填写一个普通的查询,后面的weight是一个预定义的评分方法,用来给这个查询的评分添加权重。
预定义的算分方法有以下几种:
weight
weight 使用起来最简单,只需要设置一个数字作为权重,文档的分数就会乘以该权重。
和 boost 不同,它的结果不会被规范化。例如,当 weight 为 2 时,最终评分为 2 * _score。
它最大的用途可能就是配合 filter 一起使用了,因为 filter 只会过滤出符合条件的文档,而不会计算文档的得分,所以只要满足过滤条件的文档得分都是 1,而 weight 可以把分数修改为你想要的值。
field_value_factor
用文档中的某个字段去计算分值。 比如搜索一类商品,你想在相似度排序的基础上,尽量按照商品的销售量降序,按照商品的价格升序,就可以使用这个 function。
它有以下几个属性:
field:字段名factor:乘数因子,与字段值相乘的值,默认是 1.0modifier:加工方式,可选的值有以下几种none:不加工log:计算对数log1p:先将字段值 +1,再计算对数log2p:先将字段值 +2,再计算对数ln:计算自然对数ln1p:先将字段值 +1,再计算自然对数ln2p:先将字段值 +2,再计算自然对数square:计算平方sqrt:计算平方根reciprocal:计算倒数
missing:值为 null 时的默认值
比如上面说的商品搜索,让销售量sales较大的商品尽量靠前,那么 DSL 可以这样设计
{ "query": { "function_score": { "query": { "match": { "title": "外套" } }, "field_value_factor": { "field": "sales", "modifier": "log1p", "factor": 0.1, "missing": 1 }, "boost_mode": "sum" } }}这个查询的计算公式为
_score = _score + log(1 + 0.1 * sales)random_score
产生一个 [0, 1) 的随机评分,它并不是完全随机的,而是根据种子seed、字段field、索引名、分片名来生成的随机数,所以当这四个值相同时,得到的分其实是不变的。
它具有以下属性:
seed:随机数种子field:字段名,用于生成随机数
利用这个随机评分的特性,可以实现个性化推荐之类的场景,它可以让不同用户请求得到不同结果,而同一用户请求得到相同的结果,是不是非常的 amazing 呀(毕导脸)。
例如查询一篇文章,并用 userId 产生随机评分,DSL 可以这样设计
{ "query": { "function_score": { "query": { "match": { "title": "喜欢" } }, "random_score": { "seed": 1, "field": "userId" }, "boost_mode": "replace" } }}衰减函数
衰减函数decay function提供了一个更复杂的公式,它可以让评分在多个标准之间权衡。
举个简单的例子,比如旅客搜索附近的酒店,这时候距离和价格都将影响用户的选择,有时候用户愿意为了价格便宜而选择一家比较远的酒店,而相反也可能为了住得近些付更多的钱。 这时候衰减函数可以在距离和价格上进行权衡,距离和价格就是这次查询的两个滑动标准。衰减函数可以很好的应用于数值、日期、地理位置类型的标准。
衰减函数具有以下几个属性:
origin:原点,这个字段最理想的值offset:偏移量,与原点相差在偏移量之内的值也可以获得满分scale:衰减率,当值超出原点+偏移量的范围时,它的分数就开始衰减了,scale 决定了它的衰减速度(例如,每 100 米或者每 100 元)decay:衰减值,从 origin 衰减到 scale 时所得的评分,默认是 0.5
衰减函数具有以下几种计算公式:
linear:线性衰减,每个单位距离衰减的程度是相同的exp:指数衰减,刚开始衰减时衰减速度较快,随后逐渐减缓gauss:高斯函数衰减,有一个类似 sin 的曲线,刚开始衰减速度较缓,然后突然变快,最后又逐渐变缓
下图非常直观的展示了属性和公式对衰减的影响:
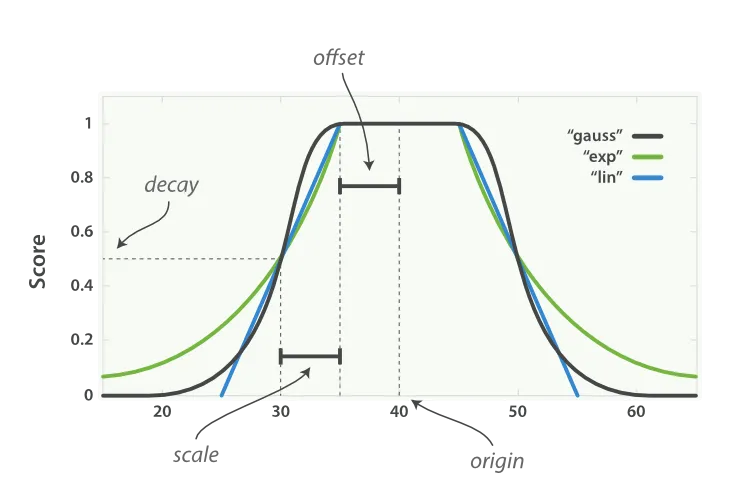
在我们的例子里,衰减函数可以这样设置
- origin 设为 120:用户最理想的酒店价格是 120 元
- offset 设为 10:用户理想的价格范围在 120 ± 10 元
- scale 设为 30:当价格超过了 130 元用户的购买欲望就开始衰减了,当价格再增加 30 元达到 160 用户就不太想买了
- decay 设为 0.5:假定价格为 120 时,用户购买欲望为 100%,价格达到 160 元时,用户购买欲望为 50%,也就是评分衰减到 0.5
- 计算公式使用 gauss:当价格超过 120 时,用户并不是立刻就不能接受,而是随着价格升高,用户的购买欲望下降越快。但是当价格特别高时,例如 500 元和 1000 元对用户来说都没什么区别,因为他都不会考虑
上面的 DSL 可以这样设计:
{ "query": { "function_score": { "query": { "match": { "title": "酒店" } }, "gauss": { "price": { "origin": "120", "offset": "10", "scale": "30" } }, "boost_mode": "sum" } }}script_score
function_score提供的以上几种 function 已经可以解决大部分问题了,但可以看出它们还有一定的局限性:
- 都只能针对一个字段计算分值
- 支持的字段类型有限,比如 field_value_factor 只能针对数字类型
如果上面的 function 都无法满足你的场景,可以使用script_score自行实现评分逻辑。它支持运行一段脚本来计算文档的分值,使用的语法是painless。
一个简单的用例如下,使用文章的点赞数votes作为它的评分
{ "query": { "function_score": { "query": { "match": { "title": "文章" } }, "script_score": { "script": { "source": "doc['votes'].value" } }, "boost_mode": "replace" } }}script_score支持给脚本传入参数,例如将点赞数的 2 倍作为文档评分:
{ "script_score": { "script": { "params": { "a": 2 }, "source": "params.a * doc['votes'].value" } }}组合多个函数
上面的例子都只使用了一个函数,如果需要多个函数组合计算评分,可以使用functions属性。
一个简单的示例:
{ "query": { "function_score": { "query": { "match_all": {} }, "boost": "5", "functions": [ { "filter": { "match": { "title": "猫咪" } }, "random_score": {}, "weight": 23 }, { "filter": { "match": { "title": "熊猫" } }, "weight": 42 } ], "max_boost": 42, "score_mode": "max", "boost_mode": "multiply", "min_score": 42 } }}functions是一个数组,其中每一个 function 都有以下属性
filter(可选):过滤查询,满足过滤条件的文档将应用这个 functionfunction(可选):具体的一个 function,比如random_scoreweight(可选):如果除了 weight 以外没有其他 function,那么 weight 的值作为评分,否则 weight 作为权重相乘
组合多个评分 function 时,可以通过score_mode属性控制组合方式:
score_mode
评分模式,表示如何合并 functions 的结果,有以下几个选项:
multiply:函数结果求积(默认)sum:函数结果求和avg:函数结果的平均值max:函数结果的最大值min:函数结果的最小值first:使用首个函数(可以有过滤器,也可能没有)的结果作为最终结果
其他属性
除了以上介绍的属性,function_score还支持一些对查询结果后处理的属性
boost
应用于整个查询的权重提升。
- boost 参数被用来提升一个语句的相对权重( boost 值大于 1 )或降低相对权重( boost 值处于 0 到 1 之间),但是这种提升或降低并不是线性的,换句话说,如果一个 boost 值为 2 ,并不能获得两倍的评分 _score 。
- 相反,新的评分 _score 会在应用权重提升之后被
归一化,每种类型的查询都有自己的归一算法。总之,更高的 boost 值会带来更高的评分 _score。
boost_mode
表示如何将函数结果与文档评分_score 进行合并,有以下几个选项:
multiply:_score 与函数值的积(默认)sum:_score 与函数值的和min:_score 与函数值间的较小值max:_score 与函数值间的较大值replace:函数值替代评分 _score
max_boost
用于限制一个函数的最大效果,例如max_boost设为 20,那么无论每个函数的计算结果如何,最终的函数结果都不会大于 20。
min_score
最终文档得分 _score 小于min_score的文档将被过滤掉。